
はじめに
突然ですが、皆さん生成AI使っていますか?筆者は仕事でもプライベートでも「何かあったらまずは生成AIに聞いてみよう!」という感じで、毎日お世話になっています。
最近は、独自の生成AIを使用している企業も増えてきましたが、この記事を読んでいる皆さんはどのように活用されていますか?
我々SIerは、社内開発以外にもお客様先に出向いてシステム構築作業を行うケースが多くあります。その際に、お客様の企業ポリシーやセキュリティ上の理由で生成AIの利用が制限されるケースがあり、現場での生成AIの利用はまだ進んでおらず、「現場における生成AI活用」に課題を感じていました。
この記事では、そのような課題を解決する(かもしれない)「閉じた環境で動作する生成AI(ローカルSLM)」をご紹介します。
前提条件
ちなみに、この記事で使用したPCのOSのバージョンとスペックは以下の通りです。
GPUは、NVIDIA社のGPUを利用しており、ご紹介する手順もNVIDIA社のGPUを使用する手順となるので、ご了承ください。
| OS | Windows 11 Home (24H2) |
| CPU | AMD Ryzen AI9 HX370 |
| メモリ | 32GB |
| ディスク | 1TB |
| GPU / VRAM | NVIDIA GeForce RTX 4060 / 8GB |
構築手順
本稿では、Windows PCに「Windows Subsystem for Linux」(以下、WSL)を導入し、WSL上のUbuntuにDockerをインストールして、ローカルSLM環境(Ollama + Open WebUI)を構築していきます。(既にWSL、Dockerを導入済みの方は、「3. ローカルSLM環境の構築」から始めてください)
1.WSLのインストール
まず、Microsoft StoreからUbuntuをインストールします。以下のURLにアクセスし、WSLのUbuntuアプリのインストーラーをダウンロードして実行してください。
URL:https://apps.microsoft.com/detail/9pdxgncfsczv?hl=ja-jp&gl=JP&ocid=pdpshare
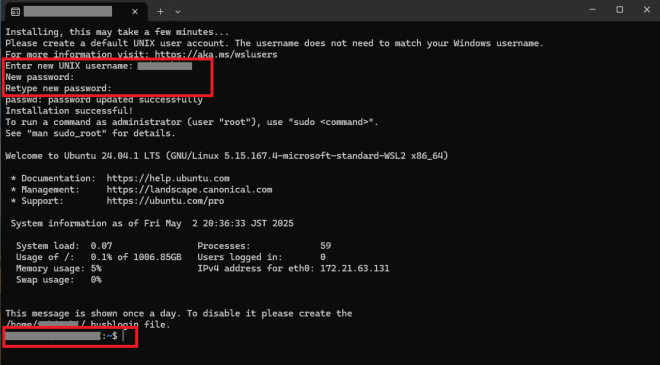
インストールが開始されると以下のようなウィンドウが起動します。少し待ち、画面の指示に従い、ユーザーIDとパスワードを入力すると使用できるようになります。( ~$ と表示され、入力待ち状態になればインストール成功です)
2.Dockerのインストール
インストールしたUbuntu環境にDockerをインストールしていきます。
まず、Ubuntuのaptパッケージを最新化し、Dockerで使用するパッケージをインストールします。
|
1 2 3 4 5 |
# aptパッケージを最新化 sudo apt update && sudo apt upgrade -y # dockerで使用するパッケージをインストール sudo apt-get install ca-certificates curl |
次に、DockerのGPGキーを作成してアクセス権を設定し、Docker用のリポジトリを docker.list に追加します。
|
1 2 3 4 5 6 7 8 9 10 |
# dockerのGPGキーの保存&アクセス設定 sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc # dockerのaptリポジトリを docker.list に追加 echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null |
再度、aptパッケージを最新化し、Dockerをインストールします。
|
1 2 3 4 |
# aptパッケージをアップデート sudo apt-get update # dockerをインストール sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin |
最後に、起動設定とDocker用のユーザーおよびグループを設定します。
|
1 2 3 4 5 6 7 8 9 |
# dockerデーモンの設定 sudo systemctl enable docker sudo systemctl enable containerd sudo systemctl start docker # docker用のユーザーとグループ設定 sudo groupadd docker sudo usermod -aG docker $USER newgrp docker |
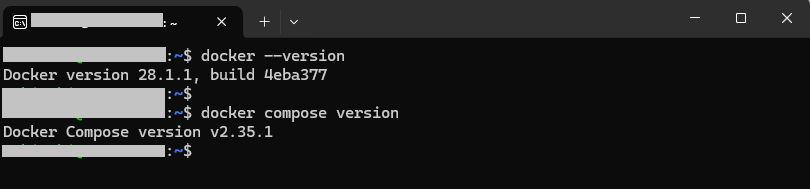
docker --version と docker compose version を実行し、正常にインストールされていることを確認します。
NVIDIA GPU搭載PCの場合は、NVIDIA Container Toolkit(以下、NVIDIA-CTK)もインストールしてください。
|
1 2 3 4 5 6 7 8 9 10 11 |
# NVIDIA-CTK取得用のリポジトリの追加とGPGキーを設定 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # aptパッケージをアップデート sudo apt-get update # NVIDIA-CTKをインストール sudo apt-get install -y nvidia-container-toolkit |
NVIDIA-CTKのインストールが完了したら、Dockerコンテナ内でGPUを認識させる設定を行います。
|
1 2 3 4 5 |
# dockerデーモンにGPUを認識させる設定 sudo nvidia-ctk runtime configure --runtime=docker # dockerの再起動 sudo systemctl restart docker |
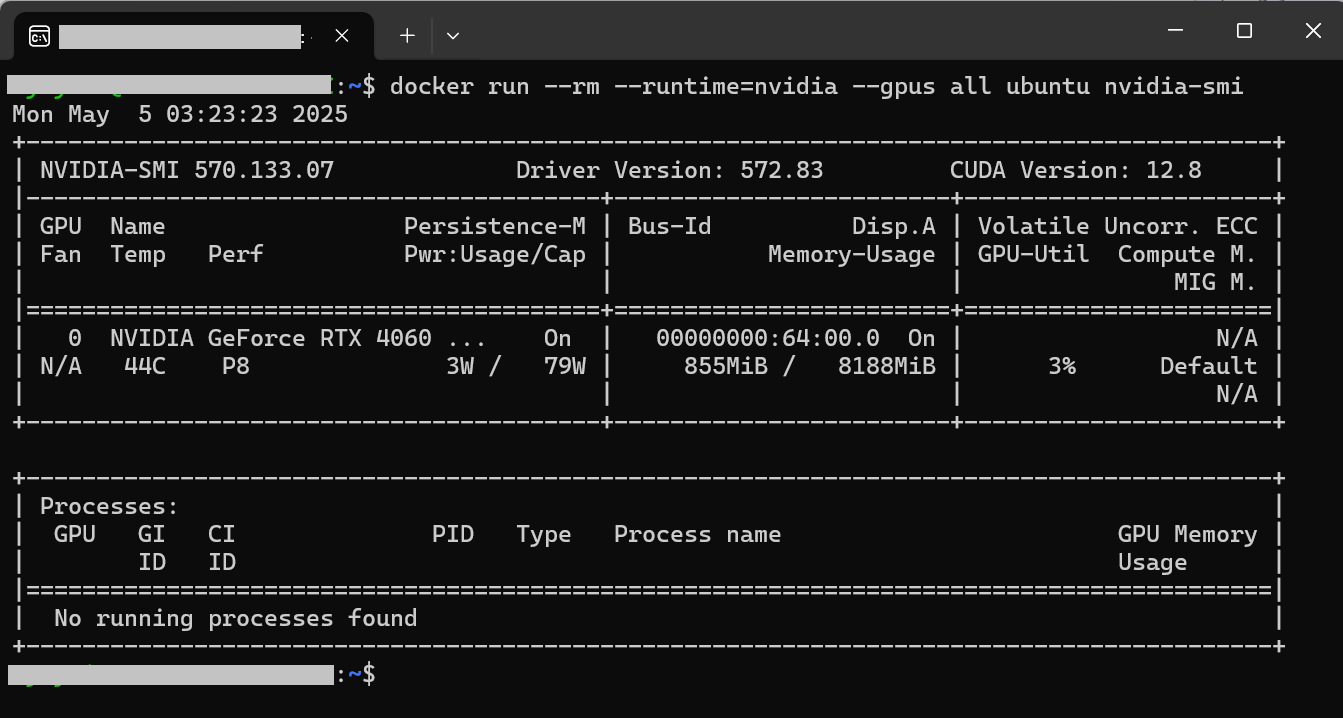
最後に、 docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi を実行し、Docker内からホストのGPUが利用できるかを確認します。以下のように表示されれば成功です。(NVIDIA-CTKのインストールに失敗している場合や、NVIDIA GPUがない場合はエラーになります。NVIDIA社以外のGPUの場合は、各ベンダーが提供しているDocker用のランタイムやドライバーが必要になります。)
これで準備は完了です。
3.ローカルSLM環境の構築
それでは、いよいよローカルSLMの構築と動作確認を行います。
今回は、モデルの推論環境としてOllama、ユーザーとの対話用WebアプリケーションとしてOpen WebUIを使用して構築していきます。個別にインストールする方式もありますが、今回はDockerのメリットを最大限に活かし、Docker Composeでまとめて構築します。
といっても、手順はすごくシンプルです。
まず、WSLのUbuntu環境にログインし、以下のコマンドを実行してユーザーのホームディレクトリ配下に
ollama フォルダを作成し、Docker Compose用の設定ファイル(
compose.yaml )を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# ホームディレクトリにollamaフォルダを作成して移動 mkdir -p ~/ollama cd ~/ollama # ollamaフォルダ直下に、compose.yaml ファイルを作成 cat <<EOF > compose.yaml services: ollama: image: ollama/ollama container_name: ollama ports: - "11434:11434" volumes: - ./ollama:/root/.ollama deploy: resources: reservations: devices: - capabilities: [gpu] driver: nvidia count: all open-webui: image: ghcr.io/open-webui/open-webui:main container_name: open-webui ports: - "8080:8080" volumes: - ./open-webui:/app/backend/data environment: API_URL: http://ollama:11434 ENABLE_OLLAMA_API: "True" OLLAMA_BASE_URLS: http://ollama:11434 WEBUI_AUTH: "False" EOF |
次に、OllamaとOpen WebUIのコンテナを起動します。
|
1 2 3 |
# ollamaディレクトリに移動し、コンテナを起動 cd ~/ollama docker compose up -d |
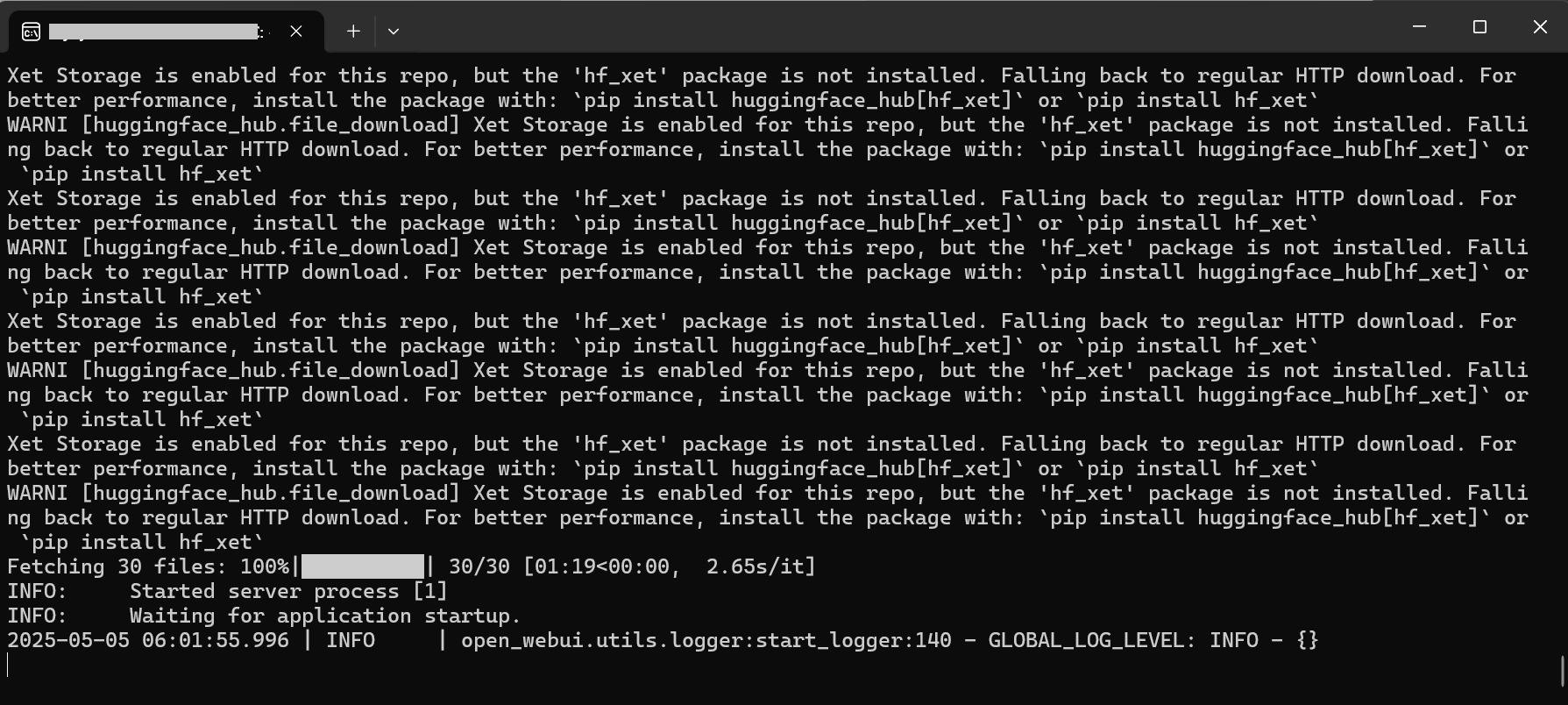
コンテナとコンテナネットワークが作成されれば成功です。 ただし、初回起動には少し時間がかかります。 起動確認は docker logs -f open-webui でOpen WebUIコンテナのログを表示し、以下のようなログが出力され入力待ち状態になれば、起動が完了したことになります。

Open WebUI側の起動が確認できたら、ブラウザで http://localhost:8080 にアクセスし、以下のような画面が表示されればOKです。
「OK、始めましょう!」ボタンをクリックした後の画面
(この例では、認証なしモードですが、ユーザー認証をさせることも可能です)
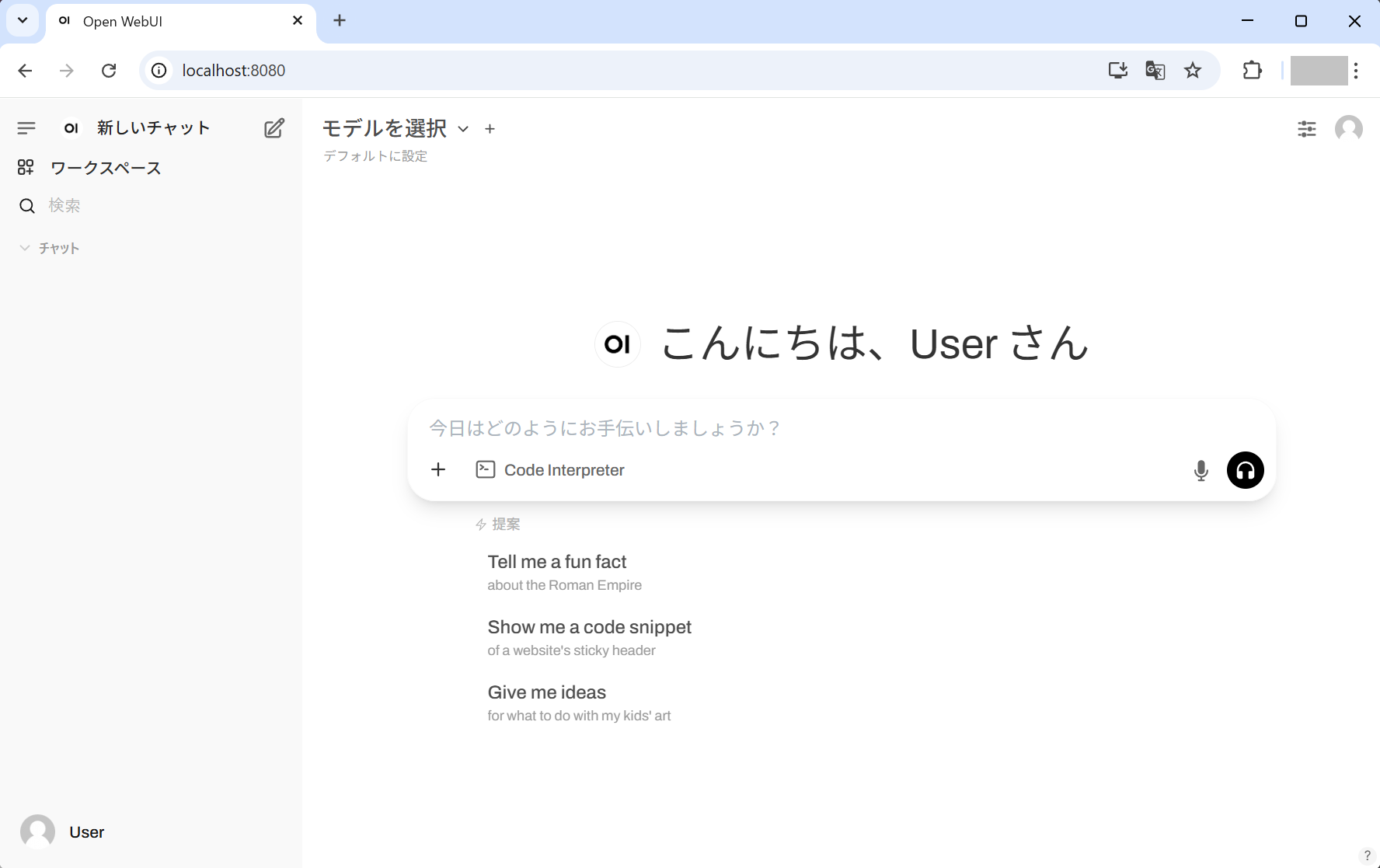
以上で、ローカルSLM環境の構築は完了です。(Dockerはこのような場合に本当に便利です!)
4.モデルの取得
次に、推論環境Ollamaのモデルを取得します。
今回は、SLM(小規模言語モデル)のMicrosoft「Phi-4」とMeta「Llama 3」を取得してみます。(Ollama自体は大規模言語モデル(LLM)の取得も可能ですが、ローカルPCで動作させるため、ここでは10GB程度のSLMを取得しています)
モデルを取得するには、まず docker compose ps を実行してOllamaコンテナが起動していることを確認します。その後、 docker compose exec ollama ollama pull [モデル名] を実行します。 モデル名 は、 Ollamaのライブラリサイトに記載されているモデルを指定します。
|
1 2 3 4 5 |
# ollamaコンテナ状態確認 docker compose ps # モデルの取得 (phi4) docker compose exec ollama ollama pull phi4:14b |
この例では phi4:14b を取得していますが、SLMといえどもサイズが9.8GBあるため、ダウンロードには多少時間がかかります。(PCのディスク容量にもご注意ください)
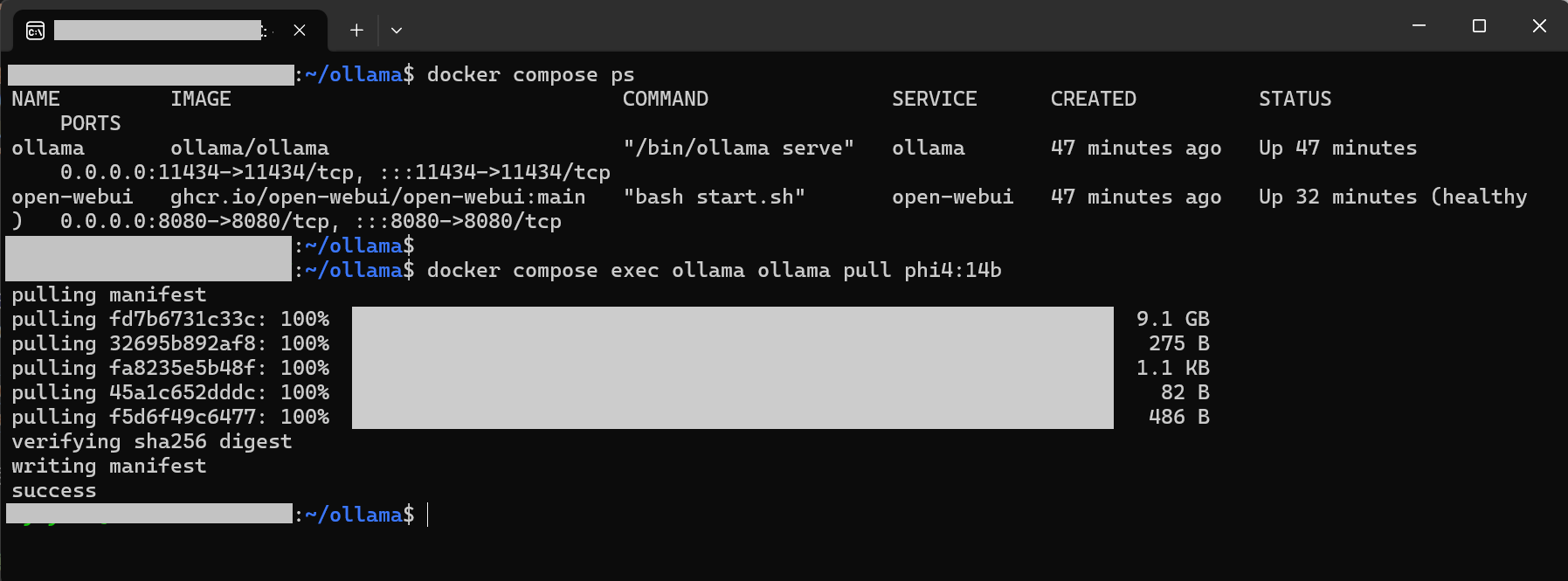
モデルの取得が完了したら、
docker compose restart open-webui でOpen WebUIコンテナを再起動します。再起動が完了した後、再度ブラウザで
http://localhost:8080 にアクセスしてください。
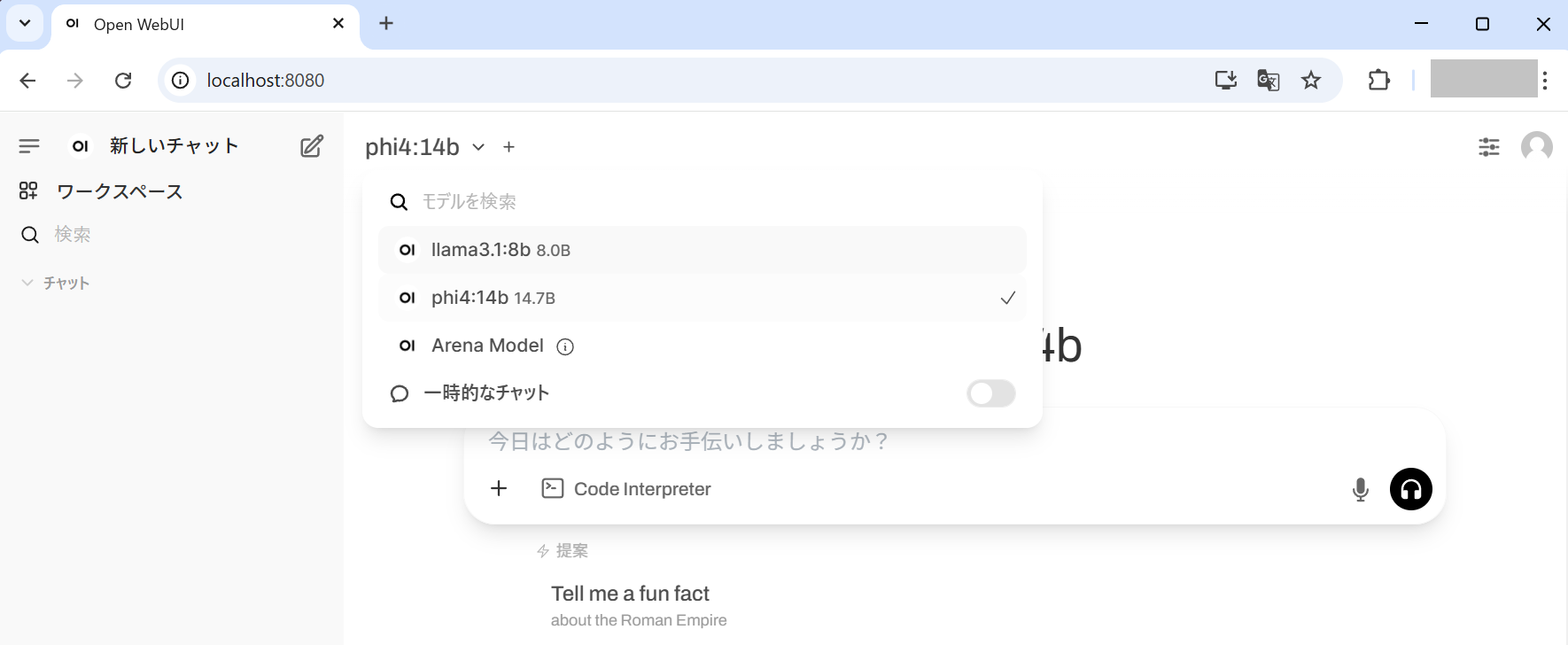
画面上部のプルダウンメニューで phi4 のモデル(phi4:14b)が表示されていれば完了です。
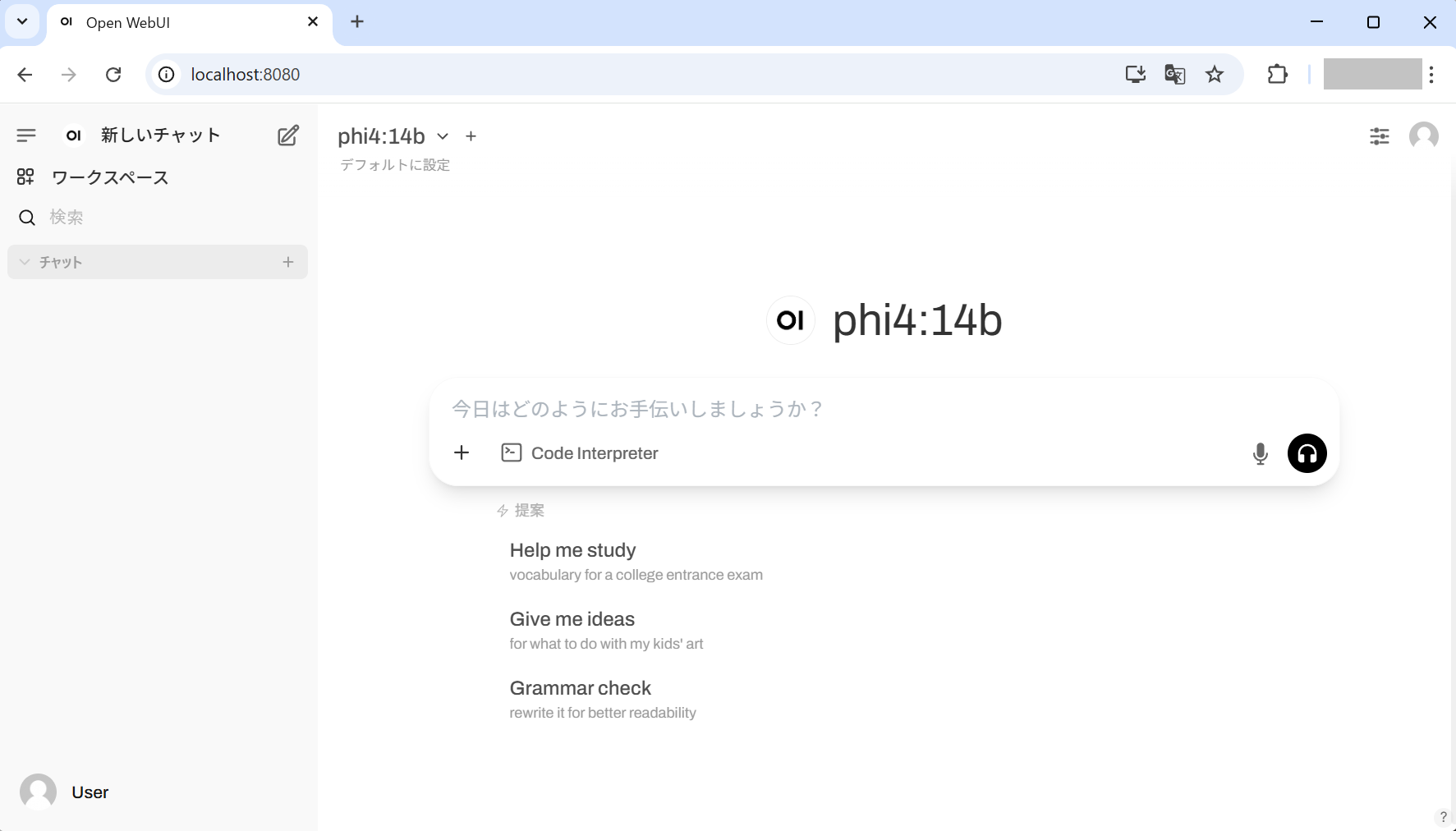
ディスク容量に余裕があれば、 docker compose exec ollama ollama pull llama3.1:8b でLlama 3.1モデルもダウンロードしてみてください。
以下に、Ollamaのモデル管理でよく利用されるコマンドを載せておきます。(このコマンドは、本稿で紹介した
compose.yaml で起動したコンテナで動作するものなのでご注意ください)
また、モデルの追加・削除後は、
docker compose restart open-webui でOpen WebUIコンテナの再起動をしてください。
| モデルの追加 | docker compose exec ollama ollama pull [モデル名] |
| モデルの削除 | docker compose exec ollama ollama rm [モデル名] |
| モデルの一覧 | docker compose exec ollama ollama ls |
( モデル名 は、Ollamaライブラリページを参照)
5.動作確認
最後に動作確認を行います。再度、ブラウザで
http://localhost:8080 にアクセスしてください。
プロンプト入力用のテキストボックスに質問を入力し、送信してみてください。今回は「こんにちは、このモデルの特徴を簡単に教えてください。」というプロンプトを入力したところ、以下のような応答が生成されました。
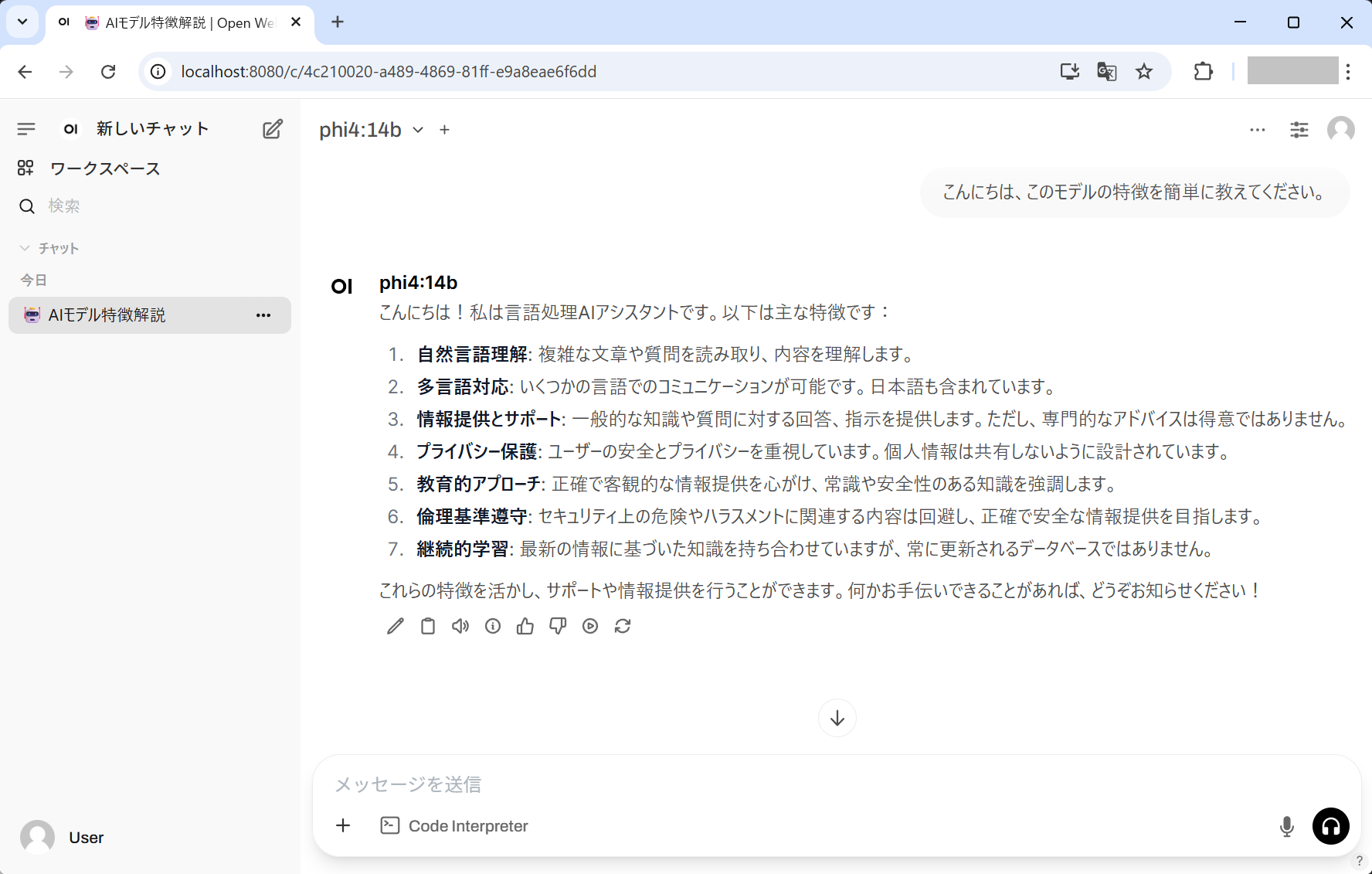
画像では応答速度がわかりにくいため、動画も用意してみました。
GPU性能にもよりますが、GeForce RTX 4060で試したところ、応答時間も比較的よく、十分に実用に耐えうるレベルではないかと感じました。
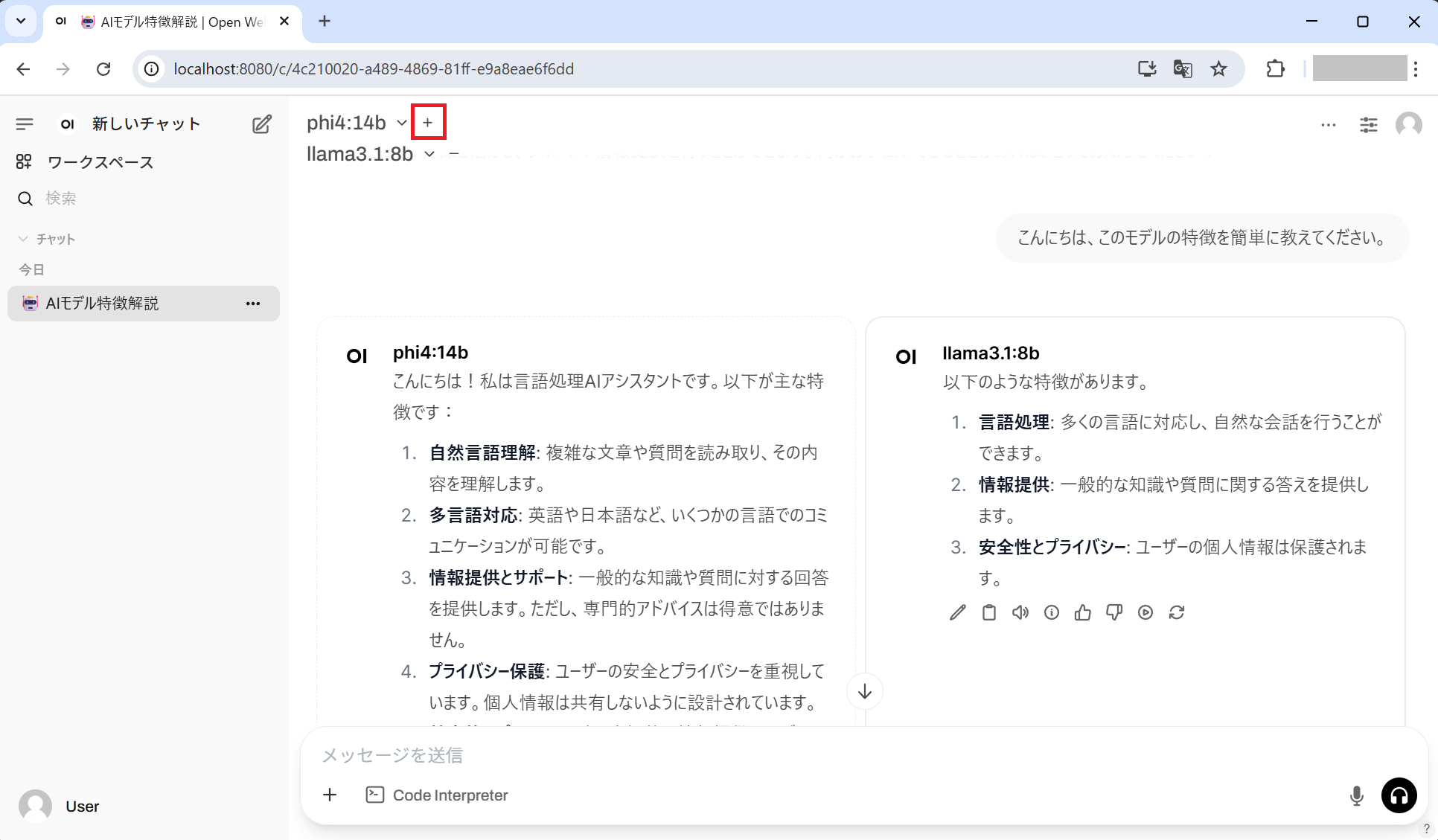
また、複数のモデルをダウンロードしている場合は、画面上部にあるモデル名の横の「+」ボタンから別のモデルを追加し、応答結果を比較することも可能です。
まとめ
今回はOllamaとOpen WebUIを使い、ローカルのPCで生成AIが試せるローカルSLM環境(※)の構築手順をご紹介しました。これで、セキュリティを気にせずAIを活用できる基盤が整いました。
(※ただ、快適に動作させるには、相応のPCスペックが必要ですが…)
この環境だけでも便利ですが、OllamaとOpen WebUIは、現場での利用を促進させるための優れた機能が用意されています。そこで次回は、この環境を発展させ、RAG(Retrieval-Augmented Generation)を構築する方法をお伝えしようと思います。
RAGを使えば、社内文書などローカルファイルの内容に基づいた応答をAIに生成させることが可能になり、現場での生成AI活用がより推進されること間違いなしです。
それでは次回の「RAG構築編」も、ぜひご期待ください!

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 社内の開発プロジェクトやクラウド・データ活用の技術サポートを担当しています。データエンジニアリングやシステム基盤づくりなど、気づけばいろんなことに首を突っ込んできましたが、やっぱり「まずは試してみる」がモットー。最近は、ローカル生成AIやコード生成AIといった、開発現場ですぐ役立つ生成AIの活用にハマり中。もっと楽に、もっとスマートにものづくりできる世界を目指して、あれこれ奮闘しています。
この執筆者の最新記事
 Pick UP!2025年7月15日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (②性能指標とログの取り方編)
Pick UP!2025年7月15日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (②性能指標とログの取り方編) Pick UP!2025年5月19日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (①環境構築編)
Pick UP!2025年5月19日ローカルSLM/閉じた環境で動作する生成AIを検証してみた (①環境構築編) Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――後編
Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――後編 Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――前編
Pick UP!2020年3月27日汎用的な仕組みでセンサーデータを見える化してみた――前編
